Przenośne programowanie równoległe architektur masywnie wielordzeniowych oraz samoadaptujące się aplikacje
Konkurs NCN: SONATA 13, panel: ST6
Nr grantu: 2017/26/D/ST6/00687
Termin rozpoczęcia: 2018-04-26
Termin zakończenia: 2022-04-25
Konkurs NCN: SONATA 13, panel: ST6
Nr grantu: 2017/26/D/ST6/00687
Termin rozpoczęcia: 2018-04-26
Termin zakończenia: 2022-04-25
Kierownik Projektu:
Zespół projektu:
Jednostka realizująca:
Na oryginalność osiągnięć naukowych projektu składają się opracowane metody i algorytmy realizujące proces dostosowania wybranych kodów aplikacji równoległych do różnorodnych platform obliczeniowych, z zachowaniem wysokiej wydajności obliczeń. Zaproponowane metody i algorytmy pozwalają na jak najpełniejszą eksploatację szerokiej gamy współczesnych architektur masywnie wielordzeniowych oraz hybrydowych. Innowacyjny charakter osiągnięć projektu w tym obszarze obejmuje:
Wśród innych osiągnięć projektu, dotyczących zagadnienia przenośnego programowania równoległych architektur masywnie wielordzeniowych, należy wymienić:
W ramach prowadzonych badań opracowano szereg metod i algorytmów umożliwiających zastosowanie zaproponowanych strategii zarządzania obliczeniami i hierarchią pamięci, w celu efektywnego wykorzystania różnorodnych cech architektur obliczeniowych. Opracowane metody znalazły swoje zastosowanie w architekturach procesorów CPU, akceleratorach GPU, układach programowalnych FPGA oraz koprocesorach Intel MIC, jak również hybrydowych rozwiązaniach powstałych z połączenia procesorów ogólnego przeznaczenia oraz akceleratorów. Zaproponowana metodyka została wykorzystana i zweryfikowana w praktyce, na przykładzie rzeczywistych aplikacji naukowych:
Przykładem uzyskanych wyników jest ogólna metoda blokowej dekompozycji obliczeń dla heterogenicznych obliczeń typu stencil, która bazuje na wykorzystaniu dwóch znanych technik optymalizacji pętli: loop fusion oraz loop tiling. Głównym celem opracowanej metody jest przezwyciężenie ograniczeń komunikacyjnych jakie nowoczesne architektury komputerowe nakładają na wykonywane obliczenia. Opracowana metoda umożliwia zmniejszenie narzutów komunikacyjnych oraz poprawę wykorzystania lokalności danych poprzez zredukowanie liczby odwołań do pamięci głównej. Rys. 1 przedstawia uproszczoną koncepcję opracowanej metody.
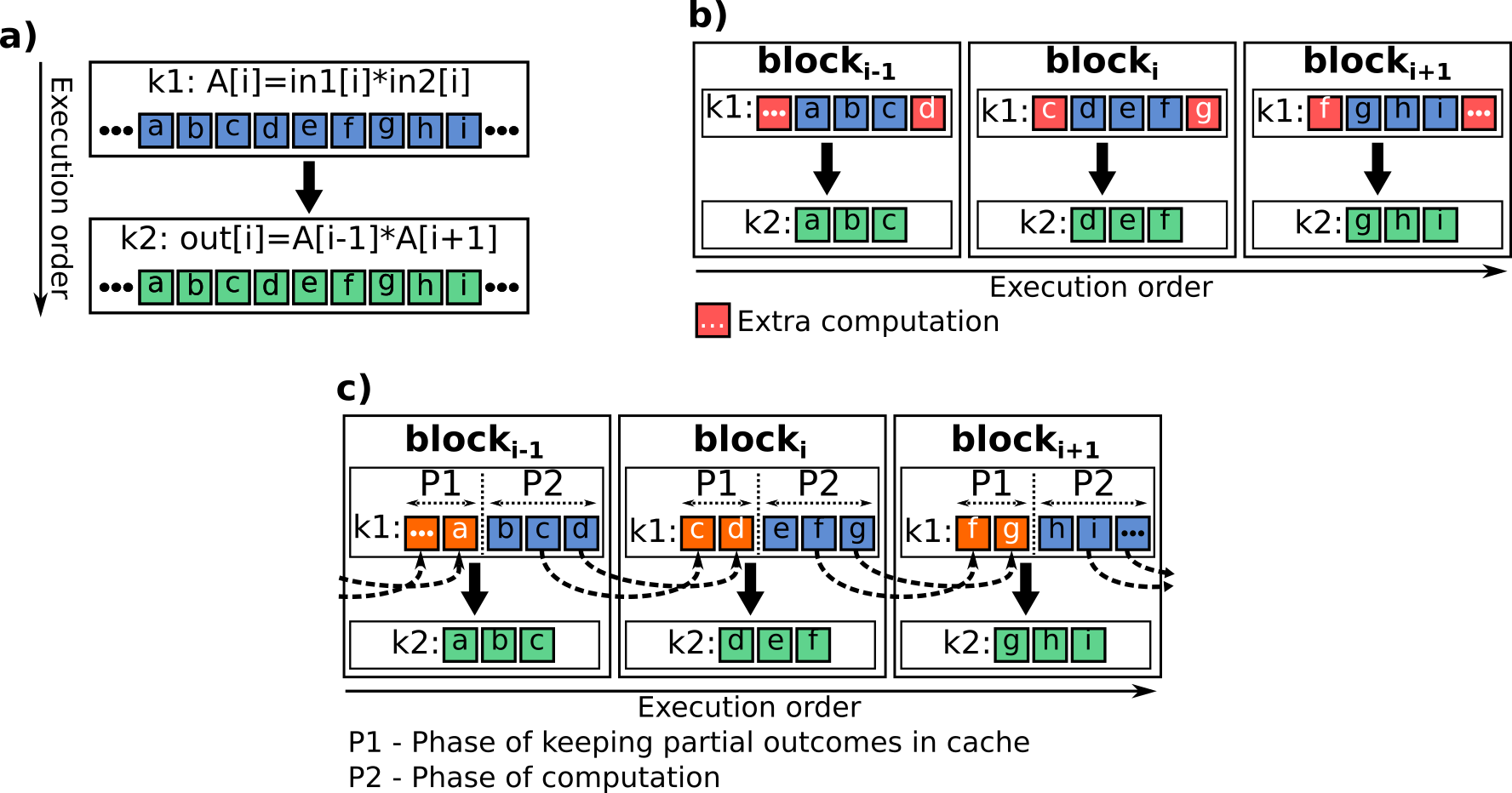
Zastosowanie zaproponowanej metody wiąże się koniecznością przeprowadzenia nadmiarowych obliczeń w ramach każdego bloku w celu zapewnienia poprawności wyników. Kluczem do zminimalizowania liczby nadmiarowych obliczeń okazał się fakt powtarzania tych samych obliczeń przez sąsiadujące bloki (Rys. 1b). Ogólna koncepcja opracowanego rozwiązania polega na pozostawianiu w pamięci podręcznej odpowiednich fragmentów tablic z danymi, zamiast wykonania obliczeń w obrębie kolejnego bloku (Rys. 1c). Aby wdrożyć metodę redukcji liczby dodatkowo wyznaczanych elementów, opracowano mechanizm mapowania obszarów pamięci podręcznej, który polega na podmianie odpowiedniej przestrzeni adresowej na potrzebę realizacji obliczeń w ramach kolejnych bloków. Opracowana metodologia została zastosowana w aplikacji MPDATA.
Kolejnym, równie interesującym przykładem jest autorska metoda dystrybucji obliczeń z wykorzystaniem przetwarzania wielordzeniowego, wielowątkowego i wektorowego (Rys. 2). Głównym zadaniem opracowanej strategii jest zapewnienie efektywnej dystrybucji obliczeń pomiędzy dostępnymi jednostkami obliczeniowymi, przy zachowaniu podstawowych zalet przedstawionej wcześniej metody. Kluczem do osiągnięcia tego celu stało się opracowanie zrównoleglenia obliczeń aplikacji MPDATA w ramach każdego bloku utworzonego w wyniku zastosowania zaproponowanej dekompozycji obliczeń. Realizacja równoległych obliczeń w zwartej formie pozwala na zredukowanie liczby odwołań do pamięci głównej poprzez wielokrotne użycie danych przechowywanych w pamięci podręcznej procesorów CPU. Jednakże, duży stopień złożoności tej metody wymusił opracowanie dedykowanego dyspozytora zadań, który rozdysponowuje obliczenia między rdzeniami, wątkami oraz jednostkami wektorowymi.
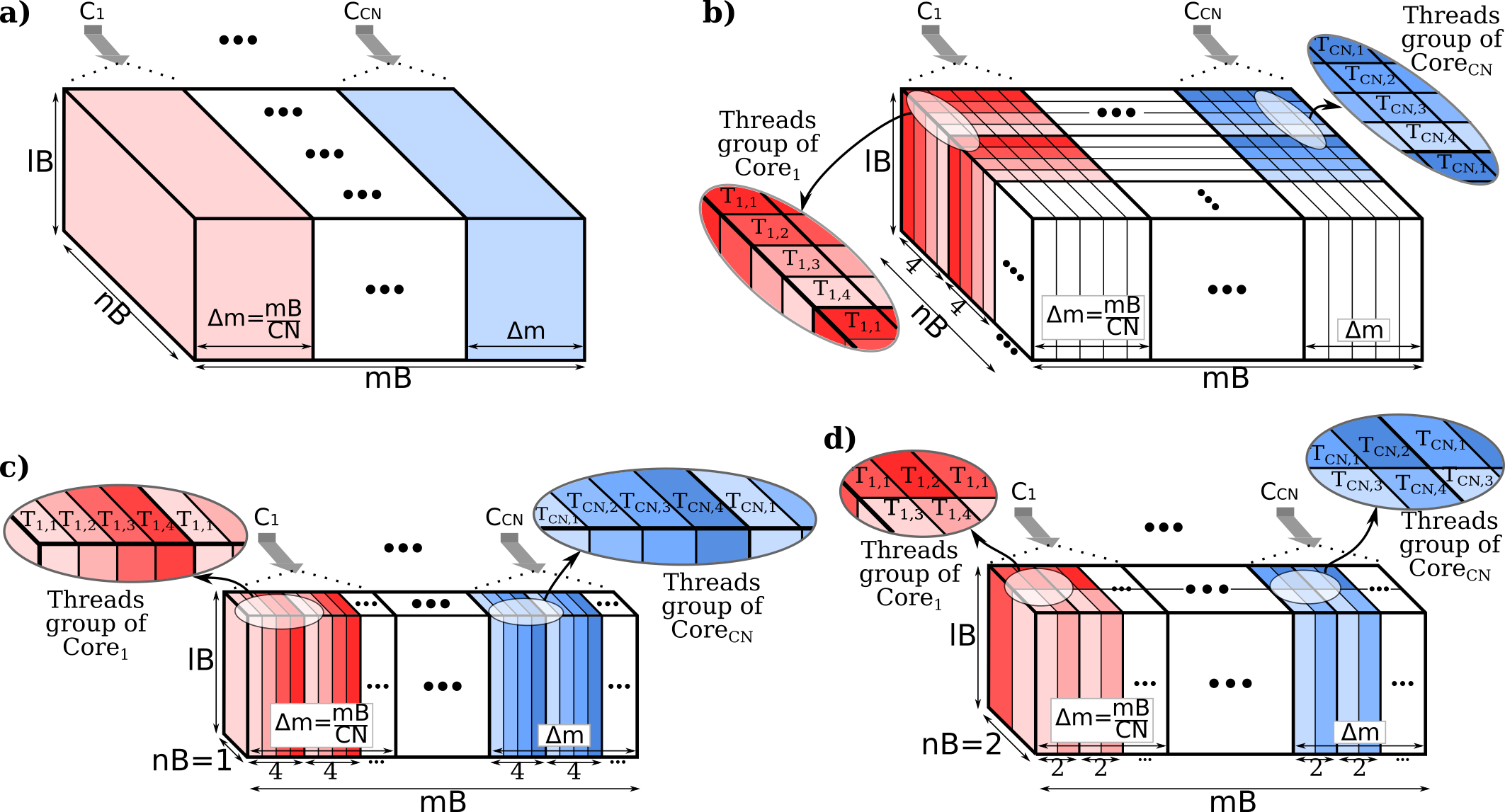
Dodatkowo, opracowana wcześniej metodologia została rozszerzona o autorską metodę grupowania dostępnych wątków obliczeniowych w ramach niezależnie funkcjonujących zespołach roboczych. Głównym założeniem tej metody jest wykonywanie obliczeń równoległych w sposób jak najbardziej niezależny. Aby osiągnąć ten cel, transfer niezbędnych danych między procesorami został zastąpiony wykonaniem dodatkowych obliczeń. Metoda ta została wdrożona do aplikacji MPDATA, pozwalając na elastyczne dopasowanie realizowanych obliczeń do szerokiej gamy nowoczesnych systemów wieloprocesorowych typu ccNUMA. W rezultacie, wybrane zespoły rdzeni wykonują więcej obliczeń, eliminując tym samym zarówno konieczność synchronizacji jednostek obliczeniowych, jak i wymóg przeprowadzania transferów danych. Proponowana metoda znalazła swoje zastosowanie nie tylko w pojedynczych węzłach obliczeniowych, ale również na poziomie klastrów obliczeniowych.
Prowadzone prace badawcze dotyczyły również opracowania algorytmu dla procesu synchronizacji obliczeń typu stencil pozwalającego na zmniejszenie kosztów synchronizacji. W odróżnieniu od standardowego podejścia typu bariera, konstrukcja opracowanego algorytmu pozwala na przeprowadzenie synchronizacji jedynie dla współzależnych wątków i rdzeni. Oznacza to, że realizacja niezależnych obliczeń równoległych nie jest wstrzymywana przez proces synchronizacji, tak jak ma to miejsce w przypadku bariery. Wdrożenie opracowanej metody wymagało przeprowadzenia szczegółowej analizy korelacji przepływów danych między rdzeniami i wątkami, jakie występują w danej aplikacji. Elastyczność opracowanego algorytmu synchronizacji umożliwiła jego wykorzystanie zarówno w algorytmie MPDATA, jak i aplikacji numerycznego krzepnięcia.
Biorąc pod uwagę charakterystyki obecnych i nadchodzących architektur obliczeniowych, zaproponowana kombinacja metod daje doskonałe możliwości do uzyskania przenośności kodu badanej aplikacji MPDATA między różnymi architekturami. Osiągnięcie tego rezultatu wiązało się z opracowaniem zarówno (i) modeli wydajnościowych dla poszukiwania kompromisu i synergii pomiędzy obliczeniami i komunikacją, jak również (ii) metody parametrycznej optymalizacji algorytmicznej z wykorzystaniem techniki automatycznego dostosowania obliczeń (autotuningu). W rezultacie zaproponowana metoda umożliwiła zautomatyzowanie procesu dostrajania kodu aplikacji MPDATA w szerokim zakresie platform obliczeniowych typu ccNUMA z zachowaniem wysokiej wydajności obliczeń.
Efektywność przedstawionej metodologii została zweryfikowana z użyciem różnorodnych systemów komputerowych. W eksperymentach została wykorzystana szeroka gama systemów komputerowych opartych na procesorach firmy Intel, w tym architekturach Intel MIC, Ivy Bridge, Haswell, Broadwell, Skylake, Cascade Lake oraz Ice Lake. Skuteczność proponowanych rozwiązań została zbadana również z użyciem nowej generacji 64-rdzeniowych procesorów serwerowych AMD EPYC bazujących na architekturze AMD ROME i AMD MILAN. W testach wykorzystane zostały platformy 1-, 2- i 4-procesorowe oraz instalacja wieloprocesorowa typu SMP/NUMA HPE SGI UV 3000. Przeprowadzone eksperymenty zdecydowanie potwierdziły skuteczność proponowanych metod odwzorowania aplikacji MPDATA na różne platformy obliczeniowe. Zastosowanie opracowanej metodologii zapewniło wysoki poziom wykorzystania zasobów obliczeniowych, zwiększając wydajność obliczeń aplikacji MPDATA nawet jedenastokrotnie oraz redukując prawie dziesięciokrotnie zużycie energii elektrycznej.
Kolejnym istotnym wynikiem prowadzonych prac badawczych było opracowanie ogólnej metodyki adaptacji wybranych aplikacji naukowych do układów programowalnych FPGA. W szczególności, w ramach prowadzonych prac została zaproponowana metoda dostosowania aplikacji MPDATA do układów Xilinx Alveo U250 FPGA. Opracowana strategia równoległej organizacji obliczeń pozwoliła przezwyciężyć ograniczenie pamięciowe badanych układów programowalnych FPGA, zwiększając wydajność obliczeń i znacznie redukując zapotrzebowanie na energię elektryczną.
Jednym z kluczowych efektów projektu było opracowanie przenośnej metodyki dostosowania wybranych aplikacji naukowych do architektur hybrydowych z akceleratorami obliczeniowymi takim jak procesory GPU oraz koprocesory Intel MIC. Istotą prowadzonych prac badawczych było dążenie do pełnego wykorzystania wszystkich komponentów architektury hybrydowej, w tym procesorów oraz akceleratorów. W szczególności, zaproponowana metodologia znalazła swoje zastosowanie w aplikacji numerycznego modelowania krzepnięcia.
W rezultacie prowadzonych prac został zaproponowany schemat równoległej organizacji obliczeń, którego struktura umożliwia jednoczesną realizację: (i) obliczeń równoległych wykonywanych przez procesory oraz akceleratory, (ii) komunikacji pomiędzy urządzeniami oraz (iii) zapisu wyników do pliku. Rys. 3 ilustruje schemat wykonania obliczeń równoległych aplikacji do modelowania krzepnięcia dostosowany do platform hybrydowych z różną liczbą akceleratorów GPU lub MIC. Opracowana metoda została rozszerzona o mechanizmy automatycznego dostosowania obliczeń do różnorodnych platform hybrydowych w celu zapewnienia dynamicznego równoważenia obciążenia pomiędzy procesorami CPU oraz akceleratorami. Efektywne wykorzystanie wszystkich komponentów platform hybrydowych wiązało się również z opracowaniem sposobu zarządzania obliczeniami, którego konstrukcja została oparta na kombinacji i eksploracji heterogenicznych środowisk programowania równoległego.
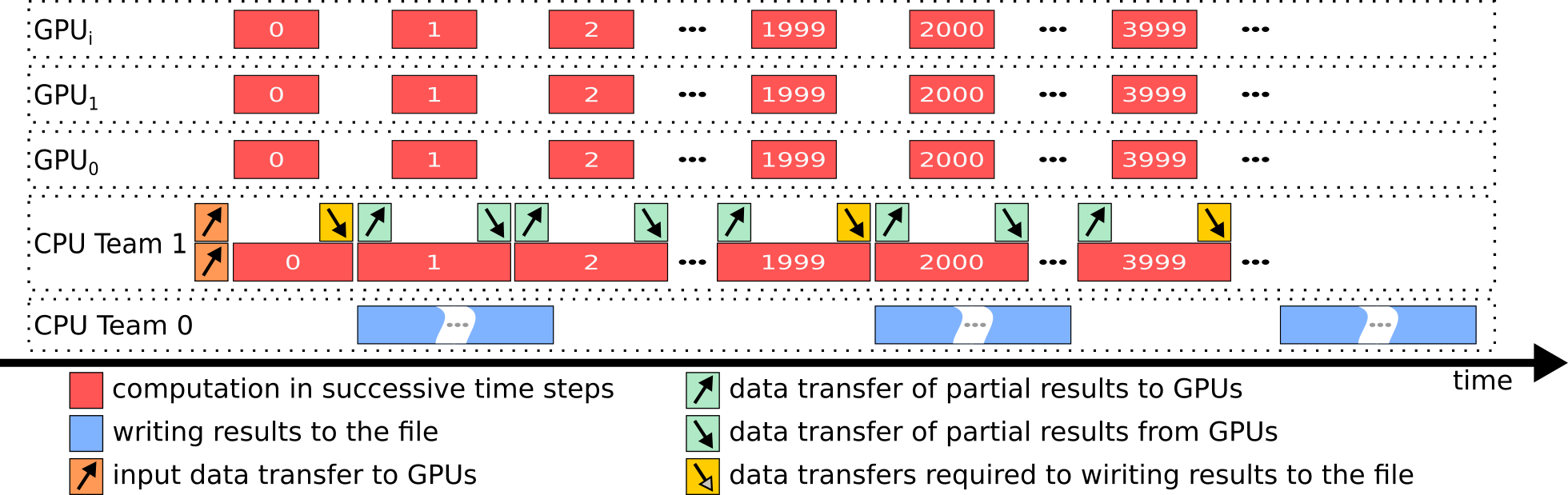
Zaproponowana metodyka adaptacji uwzględnia nie tylko efektywne zrównoleglenie oraz wektoryzację obliczeń, ale również nałożenie transferów danych na obliczenia równoległe realizowane w ramach CPU, a także odpowiedni rozkład obciążeń pomiędzy urządzeniami wraz z jednoczesnym wykonywaniem obliczeń równoległych i zapisem do pliku. W rezultacie, opracowane podejście pozwala na blisko dziesięciokrotne zwiększenie wydajności obliczeń realizowanych przez architekturę hybrydową w stosunku do podstawowej wersji aplikacji realizowanej przez dwa procesory ogólnego przeznaczenia.
Podstawowym celem projektu, który został zrealizowany w wyniku prowadzonych badań, było opracowanie metodologii dostosowywania istniejących kodów aplikacji naukowych do szerokiej gamy nowoczesnych systemów komputerowych, bazujących na procesorach oraz akceleratorach różnych firm. Strategicznym celem prowadzonych prac naukowo-badawczych było również dążenie do zapewnienia przenośności równoległych kodów badanych aplikacji, pomiędzy obecnymi, jak i pojawiającymi się systemami obliczeniowymi, z zachowaniem wysokiej wydajności obliczeń. Wśród szczegółowych celów badawczych osiągniętych w trakcie realizacji projektu należy wymienić:
Ważnym celem projektu było również prowadzenie działalności publikacyjnej oraz rozwój kadry naukowej. Realizując plan w tym zakresie opublikowano 10 artykułów w czasopismach z listy JCR, 4 artykuły w materiałach pokonferencyjnych oraz 2 kolejne prace znajdują się w przygotowaniu. Ponadto, zakończono postępowanie habilitacyjne, obroniono pracę doktorską i pracę inżynierską oraz rozpoczęto realizację kolejnego doktoratu.
Dodatkowym celem projektu stało się zagadnienie efektywnego wykorzystania systemów komputerowych do realizacji podstawowych operacji stosowanych przez algorytmy uczenia maszynowego. Podjęta tematyka jest efektem, nawiązanej w końcowej fazie projektu, współpracy z zespołem badawczym z Uniwersytetu w Buffalo, USA w obszarze zwiększania wydajności algorytmów dla zapytań zliczających. Podjęta tematyka stała się przewodnim obszarem obecnych oraz przyszłych badań realizowanych w ramach kształcenia w Szkole Doktorskiej przez członka zespołu mgr. inż. Pawła Bratka.
Realizowane cele projektu zostały również rozszerzone o zbadanie wpływu opracowywanych metod i algorytmów na korelację między wydajnością i zużyciem energii elektrycznej. Dodatkowo zaproponowana została innowacyjna metoda oraz algorytm heterogenicznego skalowania częstotliwości rdzeni w celu minimalizacji zużycia energii elektrycznej w badanych aplikacjach.
Opracowane metody i algorytmy stanowią oryginalny wkład w rozwój wiedzy ogólnej w zakresie zapewnienia wysokiej wydajności obliczeń, wykorzystywanej przez projektantów architektur i aplikacji nowej generacji. Istotnym efektem prowadzonych badań jest również zbiór eksperckiej wiedzy z obszaru efektywnego wykorzystania systemów komputerowych, o istotnym znaczeniu praktycznym dla twórców aplikacji naukowych. Proponowana metodologia stanowi istotny krok w kierunku rozwoju podstawowej wiedzy w obszarze zwiększania efektywności procesu dostosowania aplikacji naukowych do szerokiej gamy systemów obliczeniowych.
Prowadzone badania umożliwiły również podniesienie stanu wiedzy z zakresu programowania równoległego, ukierunkowanej na zapewnienie przenośności aplikacji pomiędzy różnymi architekturami masywnie wielordzeniowymi. Należy także zwrócić uwagę na wpływ projektu na rozwój teorii i praktyki obliczeń równoległych poprzez zdobycie głębokiej wiedzy i doświadczeń w zakresie budowy nowych metod, modeli i algorytmów, pozwalających na adaptację zarówno istniejącego, jak i przyszłego oprogramowania służącego modelowaniu numerycznemu do systemów obliczeniowych.
Efekty prowadzonych prac powinny pomóc w zrozumieniu ewolucji komputerów i aplikacji, m.in. poprzez nakreślenie nowych abstrakcji programistycznych dla równoległych środowisk obliczeniowych. Rezultaty projektu znajdują swoje zastosowanie, nie tylko w dyscyplinie naukowej jaką jest informatyka, ale także w takich dziedzinach, jak fizyka, chemia oraz medycyna, a także w innych dyscyplinach naukowych, w których konieczne są rozbudowane symulacje komputerowe.
Istotnym obszarem wpływu zrealizowanych badań jest umożliwienie twórcom aplikacji naukowych pełniejszego wykorzystania dostępnej mocy obliczeniowej. Znakomitym tego przykładem jest badana aplikacja MPDATA, dla której uzyskanie ponad dziesięciokrotnego zwiększenia wydajności obliczeń stwarza możliwość przeprowadzania znacznie bardziej złożonych symulacji niż kiedykolwiek wcześniej było to możliwe.